Спрос на электромобили будет увеличиваться в среднем на 38% ежегодно, согласно прогнозу по развитию рынка электромобилей в России. Соответствующие данные предоставили аналитики из консалтинговой компании Strategy Partners.
26–27 марта 2024 года в конференц-зале ЦВК «Экспоцентр» (Москва) прошла ежегодная научно-практическая конференция «Российский рынок систем электрохимического накопления электрической энергии и батарейных систем электротранспорта. Проблемы и перспективы». Эксперт «РТСофт-СГ» выступил с докладом о комплексном подходе к проектированию развития инфраструктуры заряда электротранспорта.
Одно из них – удвоение количества регистров общего назначения. В ARMv8 их 32, и в мнемониках они обозначаются как x0–x31 (младшие половины w0–w31). Следует, однако, отметить, что часть из них зарезервирована для специальных нужд: х30 – регистр адреса возврата (Lnk Register), x31 – регистр с нулевым значением (xzr).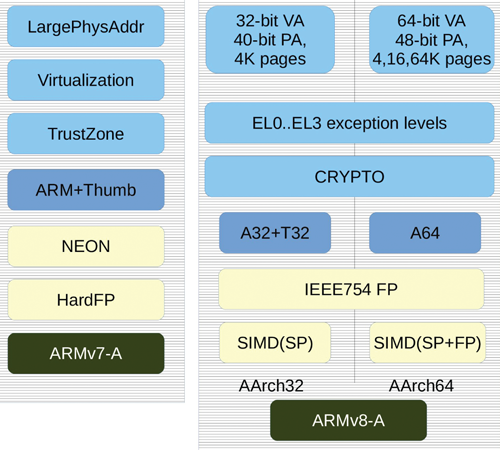
Рис. 1. Сравнение процессорных архитектур ARMv7 и ARMv8 профиля A
Изменения в регистровой модели затронули системные регистры, причём значительно сильнее, чем РОН. В ARMv8, в отличие от предыдущих версий архитектуры, нет отображения регистров. То есть если раньше регистры указателя стека, адреса возврата адреса текущей команды и состояния исполнения переключались автоматически в зависимости от режима исполнения, то теперь значительная часть регистров дублируется для разных уровней привилегий. Это значительно упрощает доступ к регистрам состояния и т. д. с более высоких уровней привилегий. Регистр указателя команд больше не является одним из РОН и доступен только для инструкций управления исполнением и некоторых режимов адресации.
Как и следовало ожидать, в режиме AArch64, вслед за моделью памяти очень значительно изменился набор инструкций, относящихся к ней. В целом набор инструкций в режиме AArch64 очень похож на то, что было раньше, но ряд особенностей, трудно реализуемых в современных процессорах, было решено оставить в прошлом. Так, в 32-битном наборе присутствовало поле предиката, позволяющее условное исполнение инструкций. В 64-битном наборе инструкций от предикатирования было решено отказаться, поскольку длина кода команды осталась той же, 32 бита, а число регистров удвоилось. Кроме того, предикатирование сильно усложняет возможности внеочередного исполнения команд ввиду дополнительных требований по переименованию регистров. В AArch64 единственными условными операциями являются инструкции перехода, выбора и сравнения.
Также в 64-битный набор инструкций не вошли встроенные сдвиги – помимо того, что место для них в кодировке операций было в дефиците, сдвигатель достаточно сложен в реализации. Сохранение прежнего формата потребовало бы удлинения исполнительного конвейера и затруднило бы достижение высоких тактовых частот.
Также в AArch64 не вошла пара инструкций LDM/ STM. Раньше эти инструкции были реализованы в микрокоде, но в кодах операций оказалось недостаточно места для списка регистров, а кроме того, такие загрузки/сохранения усложняют блоки предзагрузки данных, а реализация должна была учитывать целый ряд факторов, потенциально мешающих исполнению – исключения, прерывания и т. д. За одну инструкцию теперь можно загрузить или сохранить только 2 регистра (инструкции LDP/STP). Это позволило несколько упростить реализацию за счёт меньшей плотности кода.
Вся концепция сопроцессоров как класс не нашла места в новой архитектуре, что позволило несколько упростить некоторые моменты. Так, инструкции управления кэшем теперь не требуют сложных кодировок, а вычисления с плавающей запятой оперируют с общим архитектурным регистром флагов и не требуют пересылок в сопроцессор и обратно для выполнения сравнений.
Инструкции для вычислений с плавающей запятой также подверглись довольно значительным изменениям, в основном, в части векторных операций. В ARMv8 они, кроме присутствовавших ранее целочисленных операций и операций с одинарной точностью, включают в себя операции с двойной точностью. Изменению подвергся и формат регистров – если раньше 32 64-битных архитектурных регистра могли использоваться парами, формируя 16 виртуальных 128-битных, то теперь архитектурные регистры стали 128-битными и их 32. Поддерживается полная совместимость со стандартом IEEE754-2008. Кроме того, добавлены ин- струкции для работы с элементами векторов и редукции последних. Таким образом, этот набор инструкций по универсальности примерно соответствует x86 SSE последних версий.
Также в набор инструкций AArch64 входят в качестве необязательного элемента инструкции для вычисления криптографических хэшей и т. д., что позволяет им не отстать от конкурентов в новых для ARM-процессоров нишах, таких как серверные задачи.
Модель привилегий в ARMv8 напоминает предыдущие версии достаточно отдалённо – все режимы, ранее бывшие расширениями, теперь являются частью базовой архитектуры. Они получили названия уровней исполнения (Exception levels, дословно «уровни исключений»). Так, на уровне с минимальными привилегиями, EL0, выполняются приложения, на EL1 – ядро ОС (одно или несколько), EL2 – гипервизор (рис. 2). Наибольшие привилегии имеет уровень EL3, где выполняется доверенный код. Кроме того, в базовую спецификацию вошли и расширения безопасности, ранее известные как TrustZone. Системное ПО может выполняться в изолированной области памяти, а также объявить часть оборудования доверенным, таким образом создав изолированную среду исполнения, недоступную из основного окружения.
Изменение длины адреса естественным образом повлекло за собой изменения блока трансляции адресов (MMU). Для ядра и приложений доступны по два адресных пространства с 48 битами адреса, одно из которых отображает старшие адреса, другое – младшие (рис. 3). Однако необходимость отображения большего количества страниц памяти диктует повышенные требования к объёму памяти для размещения структур, описывающих отображаемые блоки, причём кэш буфера трансляции (TLB) должен адекватно отображать их и достаточно быстро выдавать результат трансляции. Базовая спецификация позволяет достаточно гибко подходить к вопросу построения таких таблиц – поддерживаются размеры единицы трансляции длиной в 4, 16 и 64 Кбайт (конечно же, все страницы должны быть одного размера), что позволяет увеличить процент попаданий при кэшировании таблиц. Соответственно, такие таблицы имеют до 3-х или 4-х уровней. Более того, поддерживаются специальные типы структур, описывающие блоки адресов – такие блоки могут иметь размер до 512 Гбайт. На уровнях привилегий EL2, EL3 адресное пространство только одно. Это связано с тем, что в этих режимах трансляция адресов выполняется только в один этап, в отличие от EL1, EL0, для которых трансляция может выполняться в 2 этапа (виртуальный адрес – промежуточный – физический), если это задано гипервизором.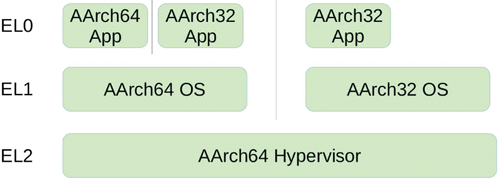
Рис. 2. Уровни привилегий
Подсистема кэша в ARMv8 поставлена в зависимость от MMU – атрибуты блоков памяти читаются из структур-описателей, поэтому для работы кэша необходимо настроить и включить MMU.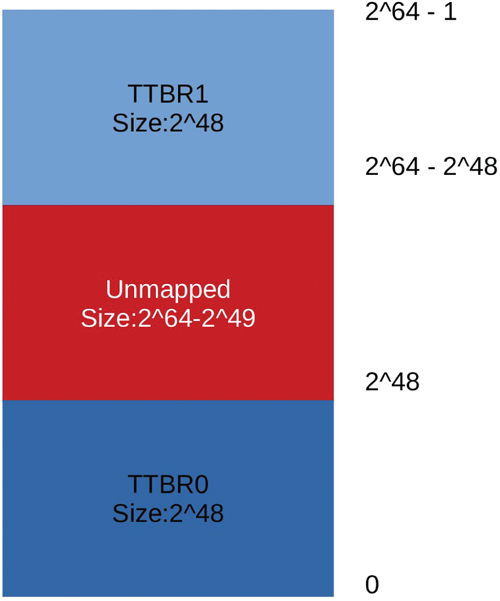
Рис . 3. Адресные пространства архитектуры ARMv8
ARMv8, подобно другим RISC-архитектурам, имеет отдельные инструкции для обращений к памяти и арифметике/логике. Режимы адресации мало измени- лись со времен ARMv7 – присутствуют все основные режимы, однако добавлена адресация относительно указателя текущей команды. Это решение связано с тем, что указатель текущей команды более не доступен напрямую. Введён так называемый режим адресации литералов, который, строго говоря, отдельным режимом не является – литералы размещаются в пределах 1 Мбайт от места обращения и обращение к ним происходит путём адресации относительно указателя команд.
В плане схемы упорядочивания операций в ARMv8 был сделан выбор в пользу упорядочивания при окончании критического участка. Атомарность в такой модели гарантирована для выровненного чтения или записи с одним РОН в качестве операнда. Выровненные пары регистров «чтение/запись» формируют пары атомарных операций, а невыровненные операции, равно как и векторные, неатомарны.
Для синхронизации предусмотрено несколько инструкций – барьеры DSB, DMB, ISB, существовавшие и в ARMv7. Первая инструкция ожидает, пока все операции чтения и записи, идущие в фоне, не закончатся, вторая – пока предыдущие обращения к памяти не станут видимыми глобально, и третья – сбрасывает исполнительный конвейер и приводит к выборке следующих инструкций из кэша или памяти.
В ARMv8 реализован набор инструкций для создания синхронизационных примитивов по типу загрузка со связью/условная запись (Load Linked/Store Conditional, LL/SC), как и в предыдущих версиях архитектуры.
Запись в этой паре происходит только при условии, когда в промежутке между ней и предыдущей загрузкой не было других записей.
Кроме того, в ARMv8 реализованы инструкции чтения с блокировкой и записи с разблокировкой. Такая пара гарантирует, что все последующие обращения к памяти будут видны остальным агентам только после выполнения первой инструкции, и до того, как завершится исполнение второй.
Следующее значительное обновление архитектуры, ARMv8.1, в рамках модели Release Consistency принесёт значительное расширение числа инструкций, предназначенных для атомарного доступа к памяти. Фактически, ARMv8.1 станет первой архитектурой, где реализованы обе концепции LL/SC и CAS (compare and swap, сравнение и обмен). Помимо этого, расширение коснётся целого набора атомарных битовых операций, таких как «и», «или» и т. д.
В плане поддержки многопроцессорных конфигураций, ARMv8 сохраняет возможности, заложенные в ARMv7, – это в первую очередь поддержка различных доменов когерентности, что позволяет значительно сократить паразитный трафик протоколов когерентности в ряде ситуаций, различные настройки когерентности таблиц трансляции и т. д.
Для ARMv8 была разработана новая инфраструктура IP-ядер, позволяющая реализовать возможности архитектуры, – это в первую очередь контроллеры прерываний: новая спецификация GICv3 определяет новые возможности, такие как локальные периферийные прерывания (LPI), сервис трансляции прерываний (ITS), масштабируемость на несколько кристаллов. Все прерывания вызываются посредством сообщений (Message Signaled Interrupts), физические линии отошли в прошлое. Новые возможности рассчитаны, в основном, на поддержку виртуализации, ввиду богатых возможностей трансляции и доставки прерываний к произвольным группам процессорных элементов и программным окружениям, формируемым для них.
Также следует отметить блоки трансляции операций ввода/вывода SMMU, предназначенные для контроля транзакций к периферийным устройствам и от них, в том числе встроенных. Они также предназначены, в основном, для поддержки виртуализации (но не только) и позволяют обеспечить трансляцию адресов, по которым происходят DMA-обращения к адресам памяти с контролем доступа.
Спецификация ARMv8 позволяет разработчикам процессорных ядер достаточно свободно подходить к реализации аппаратуры – так, множество возможностей объявлены необязательными, а для определения их поддержки конкрентным ядром есть специальные системные регистры. В настоящее время существует ряд реализаций архитектуры ARMv8, выполненных как самой компаний ARM, так и другими производителями, такими как Cavium, Qualcomm, AppliedMicro, отличающихся не только внутренним устройством, но и набором реализованных опциональных возможностей. Архитектура продолжает развиваться, и вполне очевидно, что новые версии будут её совершенствовать.

